前回ではAWS LambdaでScrapyを動かす設定を行い、検索するURLをS3のデータから行いました。
★関連記事
・AWSのLambdaでScrapyを動かす その1
・AWSのLambdaでScrapyを動かす その2 - S3からの値の取得 -
前回の記事の設定の中では値の保存を行いませんでしたのでdynamodbへの値の保存を行います。
値の取得についても分ける必要もありませんので、dynamodbからの取得に変えます。
トリガーは今まで通りS3へのアップです。
DynamoDBの設定
DynamoDBでは2つのテーブルの作成をします。
「request_table」はリクエスト対象のURLを設定したテーブルでキーは「id」で「URL」に値をセットすることになります。
「test-table」は結果を保存するテーブルでキーは「id」になります。
「request_table」にはクローリング対象のURLの項目をセットしておきます。
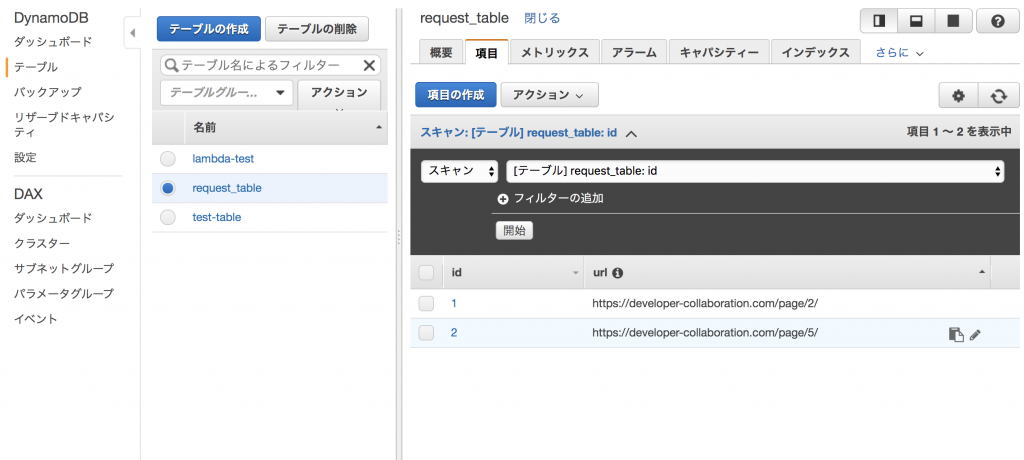
上記で準備は完了です。
クローラー側の設定
クローラー側の設定としてDynamoDBを扱うためにロールに「AmazonDynamoDBFullAccess」を追加しています。
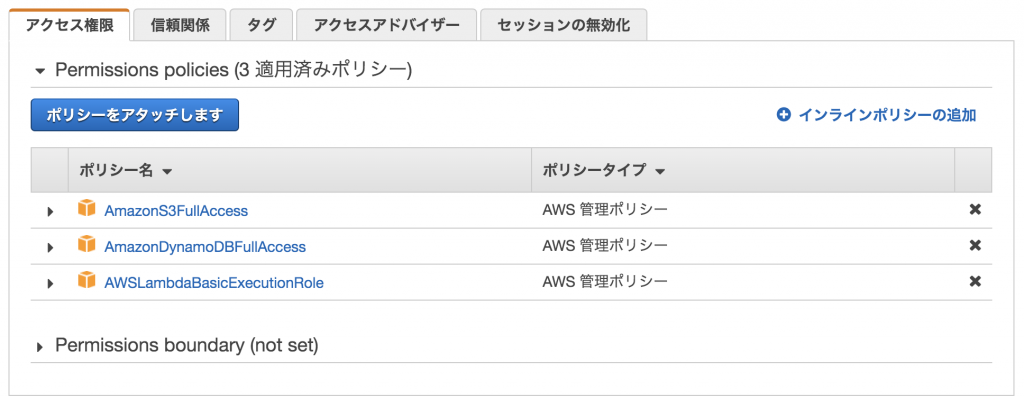
また、そちらのロールをLambdaの「実行ロール」に設定しています。
ここで「lambda_function.py」を変更してライブラリごとzipにしてアップロードしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
import boto3 import scrapy from scrapy.crawler import CrawlerProcess dynamodb = boto3.resource('dynamodb') request_table = dynamodb.Table('request_table') response_table = dynamodb.Table('test-table') class TestSpider(scrapy.Spider): name = 'testspider' def parse(self, response): for quote in response.css('article.post-list'): title = quote.css('h1.entry-title::text').extract_first() url = quote.css('a::attr(href)').extract_first() item = {'id': url, 'title': title, 'url': url } dynamo_response = response_table.put_item(Item=item) if dynamo_response['ResponseMetadata']['HTTPStatusCode'] != 200: # 失敗処理 print(dynamo_response) else: # 成功処理 pass yield item def lambda_handler(event, context): request_items = request_table.scan() start_urls_list = [] for item in request_items['Items']: start_urls_list.append(item['url']) process = CrawlerProcess({ 'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)', 'FEED_FORMAT': 'json', 'FEED_URI': '/tmp/result.json', 'HTTPCACHE_DIR': '/tmp' }) process.crawl(TestSpider, start_urls=start_urls_list) process.start() |
こちらでトリガーを起動すると(今回は前回と同じでS3へのアップロード)、CloudWatchでのログが確認できます。
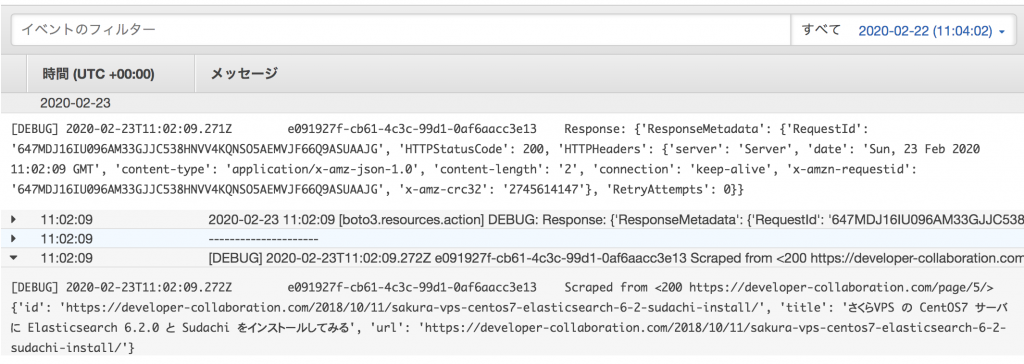
上記でDynamoDBからのレスポンスと登録している内容(yieldの値)が確認できます。
DynamoDBでもデータが増加しています。
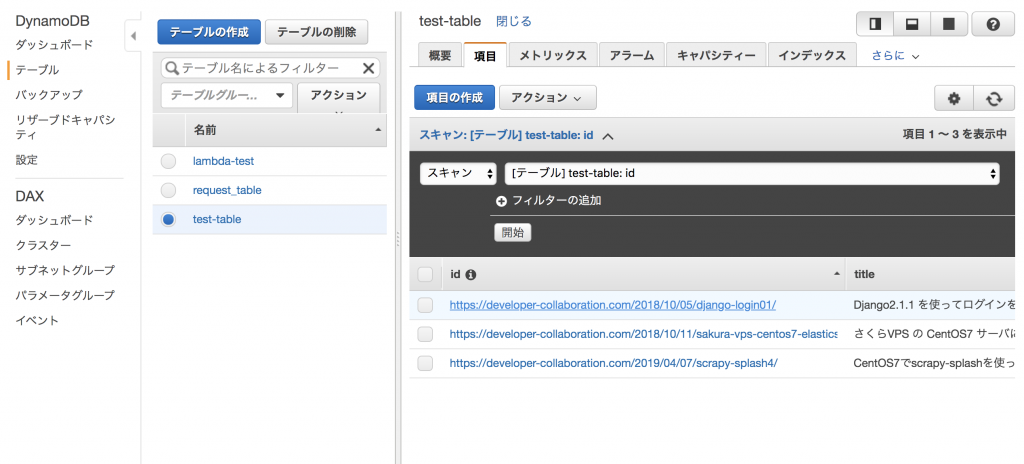
本来的にはItemPipelineを使った方が良いかもしれませんが、実行としてはこちらの方がシンプルなのでこちらの実装にしました。
これでかなり広がりのあるクローラーをServerlessで構築することができます。
★関連記事
・AWSのLambdaでScrapyを動かす その1
・AWSのLambdaでScrapyを動かす その2 - S3からの値の取得 -
このブログは株式会社CoLabMixによる技術ブログです。
GCP、AWSなどでのインフラ構築・運用や、クローリング・分析・検索などを主体とした開発を行なっています。
Ruby on RailsやDjango、Pythonなどの開発依頼などお気軽にお声がけください。
開発パートナーを増やしたいという企業と積極的に繋がっていきたいです。