さて、前回に引き続きElasticsearchの設定です。
★関連記事
Elasticsearch 6 を使ったデータ検証 その1(Dockerでコンテナの作成と確認)
Elasticsearch 6 を使ったデータ検証 その2(マッピングの登録をしてみる)
Elasticsearch 6 を使ったデータ検証 その3(bulkでデータを投入してみる)
Elasticsearch 6 を使ったデータ検証 その4(チュートリアル記事とデータの検索での比較)
Elasticsearch 6 を使ったデータ検証 その5(クエリでの検索)
Elasticsearch 6 を使ったデータ検証 その6(Aggregationを使った分類・集計)
今回はテキスト分析のキモになるAnalysisについて。
Analysisについて
Analysisは、「検索のクエリの文字列」と「インデックスに格納している文書」がヒットするように、格納する文章、クエリの文字列ともに、単語の単位で分割する手法です。
例えば以下のような例です。

文書をAnalyzerを使って分割を行います。
日本語はスペース(空白)などで単語が分割されないので、形態素解析用の「kuromoji Analysis Plugin」と呼ばれるプラグインを使って分割することが多いです。
尚、文章を解析するときに「表記の揺れ」を抑えるルールとしては以下のようなものがあります。
・ステミング
語形の変化を取り除いて、同一表現の単語に分割する処理。
「love、loving、lovingly」 => 「love」、「歩く」 =>「歩」
・ノーマライズ(正規化)
データを利用しやすいように整形すること。
例えば全角文字を半角文字に揃える、大文字を全て小文字に揃える、カタカナを平仮名に揃えるなど、単語単位での表記の揺れに対応します。
・ストップワード
文章中の自然言語の中で、一般的などの理由で単語自体に意味を持たない単語を対象外にする処理。
英語では「the」や「a」や「for」などの冠詞、前置詞や助詞などを除外することが多い。
Analyzerの定義方法
マッピング定義でフィールドとそのデータ型が定義できますが、そこでAnalyzerを指定できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
$ curl -H "Content-Type: application/json" -XPOST 'http://localhost:9200/restaurant/type?pretty=true' -d ' > { > "mappings": { > "my_type": { > "properties": { > "my_analyzer": { > "type": "text", > "analyzer": "standard" > } > } > } > } > } > ' { "_index" : "restaurant", "_type" : "type", "_id" : "Nb1pZWUBgL_jM1_nw2mB", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 } |
上記では「my_analyzer」という名前でAnalyzerを定義して、こちらを指定すると「standard Analyzer」による単語分割が行われるようになります。
尚、Analyzerはフィールド単位で設定しますが、設定するとインデックス格納時だけでなく、クエリ実行時にもここで指定したAnalyzerが使われます。
Analyzerの構成要素
Analyzerでは内部では、「Char filter」、「Tokenizer」、「Token filter」の3つのブロック処理から構成されています。
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-custom-analyzer.html
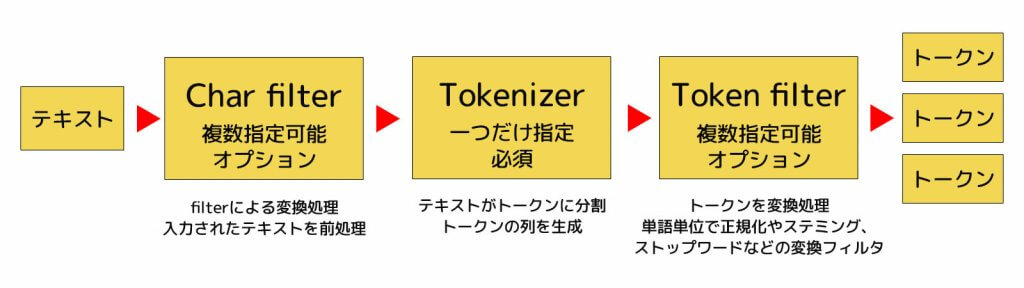
まず、テキストが「Char filter」を通り、各filterによる変換処理が行われます。
次にテキストが「Tokenaizer」によってトークン(単語)に分割されます。
最後に各トークンは「Token filter」により変換処理が行われます。
Char filter
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html
「Char filter」は入力されたテキストを前処理するためのフィルタ機能です。
HTMLのタグの除去やマッピングによるルールの変換など、単語分割を行う前の変換処理を行います。
次の3種類のビルトイン「Char filter」が提供されており、「custom analyzers」で利用することができます。
・HTML Strip Character Filter
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-htmlstrip-charfilter.html
HTMLフォーマットのテキストに含まれるタグを除外します。
特定のタグは除外対象から除くなどの設定もできます。
「<p>」 => 除外
・Mapping Character Filter
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-mapping-charfilter.html
入力文字に含まれる特定の文字に対してマッピングルールを定義しておき、ルールに基づいた変換処理を行います。
「:(」 => 「_sad_」
・Pattern Replace Character Filter
定義された正規表現ルールに基づいて入力文字の変換処理を行います。
「123-456-789」 => 「123_456_789」
Tokenizer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
Tokenizerは受け取ったテキストに対して分割処理を行い、トークン(単語)の列を生成します。
Tokenizerは大きく分けて3種類の機能群に分類でき、「custom analyzers」で利用することができます。
・単語分割用のTokenizer
空白などの単語の区切りなどから、トークン(単語)に分割します。
「Standard Tokenizer」、「Letter Tokenizer」、「Lowercase Tokenizer」、「Whitespace Tokenizer」、 「UAX URL Email Tokenizer」、「Classic Tokenizer」、「Thai Tokenizer」が提供されています。
・N-Gramでの単語分割用のTokenizer
単語を小さなフラグメントにします。
「N-Gram Tokenizer」と「Edge N-Gram Tokenizer」が提供されています。
・構造化テキスト分割用のTokenizer
メールアドレス、郵便番号やファイルパスなどの構造化テキストを分割します。
「Keyword Tokenizer」、「Pattern Tokenizer」、「Simple Pattern Tokenizer」、「Simple Pattern Split Tokenizer」、「Path Tokenizer」が提供されています。
Token filter
「Token filter」はTokenizerが分割したトークンに対して、変換処理を行います。
デフォルトでは、「Standard Token Filter」、「ASCII Folding Token Filter」、「Flatten Graph Token Filter」、「Length Token Filter」、「Lowercase Token Filter」、「Uppercase Token Filter」、「NGram Token Filter」、「Edge NGram Token Filter」、「Porter Stem Token Filter」、「Shingle Token Filter」、「Stop Token Filter」、「Word Delimiter Token Filter」、「Word Delimiter Graph Token Filter」、「Stemmer Token Filter」、「Stemmer Override Token Filter」、「Keyword Marker Token Filter」、「Keyword Repeat Token Filter」、「KStem Token Filter」、「Snowball Token Filter」、「Phonetic Token Filter」、「Synonym Token Filter」、「Synonym Graph Token Filter」、「Compound Word Token Filters」、「Reverse Token Filter」、「Elision Token Filter」、「Truncate Token Filter」、「Unique Token Filter」、「Pattern Capture Token Filter」、「Pattern Replace Token Filter」、「Trim Token Filter」、「Limit Token Count Token Filter」、「Hunspell Token Filter」、「Common Grams Token Filter」、「Normalization Token Filter」、「CJK Width Token Filter」、「CJK Bigram Token Filter」、「Delimited Payload Token Filter」、「Keep Words Token Filter」、「Keep Types Token Filter」、「Classic Token Filter」、「Apostrophe Token Filter」、「Decimal Digit Token Filter」、「Fingerprint Token Filter」、「Minhash Token Filter」、「Character Filters」、「HTML Strip Char Filter」、「Mapping Char Filter」、「Pattern Replace Char Filter」と非常に多くのフィルタがあります。
利用頻度の多いToken filterは以下の4つです。
・Lowercase Token Filter
トークンの文字を全て小文字に変換するフィルタです。
・Stop Token filter
ストップワードの除去を行うフィルタです。言語ごとにデフォルトのストップワードリストが定義されています。
ストップワードリストのカスタマイズも可能です。
・Stemmer Token filter
言語ごとに定義されたステミング(語幹)処理を行うフィルタです。
・Synonym Token filter
類義語(シノニム)を正規化して一つの単語に変換するためのフィルタです。
「universe」、「cosmos」など、同じ「宇宙」という意味を持つ単語を、すべて「cosmos」に変換して揃えるなどしてくれます。
ビルトインで提供されているAnalyzer
ビルトインで提供されているAnalyzerは以下などがあります。
・Standard Analyzer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-standard-analyzer.html
| Char filter | なし |
| Tokenizer | Standard Tokenizer |
| oken filter | Standerd Token Filter Lower Case Token Fileter Stop Token Filter |
・Simple Analyzer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-simple-analyzer.html
| Char filter | なし |
| Tokenizer | Lower Case Tokenizer |
| Token filter | なし |
・Whitespace Analyzer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-whitespace-analyzer.html
| Char filter | なし |
| Tokenizer | Whitespace Tokenizer |
| Token filter | なし |
・Stop Analyzer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-stop-analyzer.html
| Char filter | なし |
| Tokenizer | Lower Case Tokenizer |
| Token filter | Stop Token Filter |
・Keyword Analyzer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-keyword-analyzer.html
| Char filter | なし |
| Tokenizer | Keyword Tokenizer |
| Token filter | なし |
・Pattern Analyzer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-pattern-analyzer.html
| Char filter | なし |
| Tokenizer | Pattern Tokenizer |
| Token filter | Lower Case Token Filter Stop Token Filter |
・Language Analyzer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-lang-analyzer.html
以下の言語パターンに対応しています。
arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english, finnish, french, galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, persian, portuguese, romanian, russian, sorani, spanish, swedish, turkish, thai.
それぞれ固有のStopwordsやステミングなどが設定されています。
Language Analyzerは「custom」として設定できます。
・Fingerprint Analyzer
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-fingerprint-analyzer.html
| Char filter | なし |
| Tokenizer | Standard Tokenizer |
| Token filter | Lower Case Token Filter ASCII Folding Token Filter Stop Token Filter Fingerprint Token Filter |
Analyzerのカスタム定義
Analyzerをカスタムで定義するには以下のような形で定義を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
$ curl -H "Content-Type: application/json" -XPOST 'http://localhost:9200/restaurant/type?pretty=true' -d ' > { > "settings": { > "analyzer": { > "my_analyzer2": { > "type": "custom", > "char_filter": [ "html_strip"], > "tokenizer": "standard", > "filter": [ "lowercase", "stop"] > } > } > } > } > ' { "_index" : "restaurant", "_type" : "type", "_id" : "N72GaWUBgL_jM1_n32kD", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 } |
日本語を扱うAnalyzerの導入と設定
日本語を扱うAnalyzerはプラグインで追加インストールできます。
現在、日本語を扱えるプラグインは、「ICU Analyzis Plugin」と「kuromoji Analysis Plugin」の2種類あります。
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis.html
「ICU Analyzsis Plugin」は「International Components for Unicode」ライブラリーを使用しており、アジア系言語に対応したプラグインで、文字列境界の解析やUnicode変換など様々なことを実施してくれるプラグインです。
「kuromoji Analysis Plugin」はオープンソースの日本語形態素解析エンジンである「kuromoji」をElasticsearchに統合したプラグインです。
「kuromoji」はアティリカが開発したオープンソースの日本語形態素解析器で、単語の分割、品詞タグ付け、 見出し化、漢字の読み方や、複数の辞書のバックエンドをサポートしています。
kuromoji Analisis Pluginの設定
kuromojiの設定は以下のように行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
$ curl -H "Content-Type: application/json" -XPOST 'http://localhost:9200/restaurant/type?pretty=true' -d ' > { > "properties": { > "new_user_name": { > "type": "text", > "analyzer": "kuromoji" > } > } > } > ' { "_index" : "restaurant", "_type" : "type", "_id" : "Nr0lZmUBgL_jM1_nMml6", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 } |
また、Analyzerだけでなく「Char filter」、「Tokenizer」、「Token filter」にも、 「kuromoji」に対応したビルトイン機能がいくつか提供されています。
Char filter
kuromoji_iteration_mark
日本語の踊り文字(々、ゞなど)を正規化するフィルタ
「時々」 => 「時時」
Tokenizer
「kuromoji_tokenizer」はkurojojiを用いた日本語形態素解析を行うTokenizerです。
動作をコントロールするための設定が3種類あります。
mode
normal
単語が分割されないモード
「関西国際空港」 => 「関西国際空港」
「アブラカダブラ」 => 「アブラカダブラ」
search
単語を最小単位に分割し、長い単語も合わせて含むモード
「関西国際空港」 => 「関西」、「国際」、「空港」、「関西国際空港」
「アブラカダブラ」 => 「アブラカダブラ」
extended
わからない単語は1文字分割の1-gramとして分割するモード
「関西国際空港」 => 「関西」、「国際」、「空港」
「アブラカダブラ」 => 「ア」、「ブ」、「ラ」、「カ」、「ダ」、「ブ」、「ラ」
デフォルトは「search」モードです。
discard_punctuation
「true」と指定した場合は句読点を除外します。
デフォルトは「true」です。
user_dictionary
ユーザー辞書ファイルを使う場合にそのファイルパスを指定します。
Token filter
kuromoji_baseform
動詞や形容詞などの活用で語尾が変わっている単語をすべて基本形に揃えるフィルタ
(例:"大きく" → "大きい")
kuromoji_part_of_speech
助詞などの不要な品詞を指定に基づいて削除するフィルタ
(例:"東京の紅葉情報" → 助詞の"の"を削除)
kuromoji_readingform
漢字をその読み仮名に変換するフィルタ
「寿司」 => 「スシ」もしくは「sushi」
kuromoji_stemmer
語尾の長音を削除するフィルタ
「コンピューター」 => 「コンピュータ」
ja_stop
日本語用のストップワード除去フィルタです。デフォルトのままでも「あれ」、「それ」などを除去してくれます。
「これ欲しい」 => 「欲しい」
kuromoji_number
漢数字を数字に変換するフィルタ
「五000」 => 「5000」
kuromojiでの検索
「"explain": true」を追加すると、トークンだけでなく読みや品詞といった情報もとることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
$ curl -H "Content-Type: application/json" -XGET 'http://localhost:9200/_analyze?pretty=true' -d ' > { > "tokenizer" : { "type" : "kuromoji_tokenizer", "mode" : "extended" }, > "text" : "関西国際空港", > "explain": true > } > ' { "detail" : { "custom_analyzer" : true, "charfilters" : [ ], "tokenizer" : { "name" : "_anonymous_tokenizer", "tokens" : [ { "token" : "関西", "start_offset" : 0, "end_offset" : 2, "type" : "word", "position" : 0, "baseForm" : null, "bytes" : "[e9 96 a2 e8 a5 bf]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-固有名詞-地域-一般", "partOfSpeech (en)" : "noun-proper-place-misc", "positionLength" : 1, "pronunciation" : "カンサイ", "pronunciation (en)" : "kansai", "reading" : "カンサイ", "reading (en)" : "kansai", "termFrequency" : 1 }, { "token" : "国際", "start_offset" : 2, "end_offset" : 4, "type" : "word", "position" : 1, "baseForm" : null, "bytes" : "[e5 9b bd e9 9a 9b]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : "コクサイ", "pronunciation (en)" : "kokusai", "reading" : "コクサイ", "reading (en)" : "kokusai", "termFrequency" : 1 }, { "token" : "空港", "start_offset" : 4, "end_offset" : 6, "type" : "word", "position" : 2, "baseForm" : null, "bytes" : "[e7 a9 ba e6 b8 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : "クーコー", "pronunciation (en)" : "kuko", "reading" : "クウコウ", "reading (en)" : "kuukō", "termFrequency" : 1 } ] }, "tokenfilters" : [ ] } } |
長くなりましたが一旦、Elasticsearchでの検証は終了です。
★関連記事
Elasticsearch 6 を使ったデータ検証 その1(Dockerでコンテナの作成と確認)
Elasticsearch 6 を使ったデータ検証 その2(マッピングの登録をしてみる)
Elasticsearch 6 を使ったデータ検証 その3(bulkでデータを投入してみる)
Elasticsearch 6 を使ったデータ検証 その4(チュートリアル記事とデータの検索での比較)
Elasticsearch 6 を使ったデータ検証 その5(クエリでの検索)
Elasticsearch 6 を使ったデータ検証 その6(Aggregationを使った分類・集計)
このブログは株式会社CoLabMixによる技術ブログです。
GCP、AWSなどでのインフラ構築・運用や、クローリング・分析・検索などを主体とした開発を行なっています。
Ruby on RailsやDjango、Pythonなどの開発依頼などお気軽にお声がけください。
開発パートナーを増やしたいという企業と積極的に繋がっていきたいです。
お問い合わせやご依頼・ご相談など