AWS Lambda でS3にファイルがアップロードされたら、加工して別フォルダにファイルを作成する(Python)
さて、前回に続き AWS Lambda での少し複雑になった設定を今回は Python で。
【関連記事】
・AWS LambdaでS3にファイルがアップロードされたのを検知する
・外部のライブラリを利用してのAWS Lambdaの設定
・AWS Lambdaをpython-lambda-localとlambda-uploaderを使ってローカル開発してみる
AWS Lambda で実行する環境について
今回はS3の特定バケットのフォルダ上にinputファイルが置かれた時に、そのS3イベントを検知してCSVファイルをJSONに加工して別フォルダに置くという動作をやってみます。
| バケット | s3://sample-app01.developer-collaboration.com |
| inputのフォルダ(CSVを置く) | sample-app01.developer-collaboration.com/input |
| outputのフォルダ(JSONを置く) | sample-app01.developer-collaboration.com/output |
inputのフォルダにファイルがアップされるイメージです。
inputのファイルは以下のようなファイルです。
|
1 2 3 4 |
1,テスト,AAA 2,テスト2,BBB |
関数名は「csvExtractor」とします。
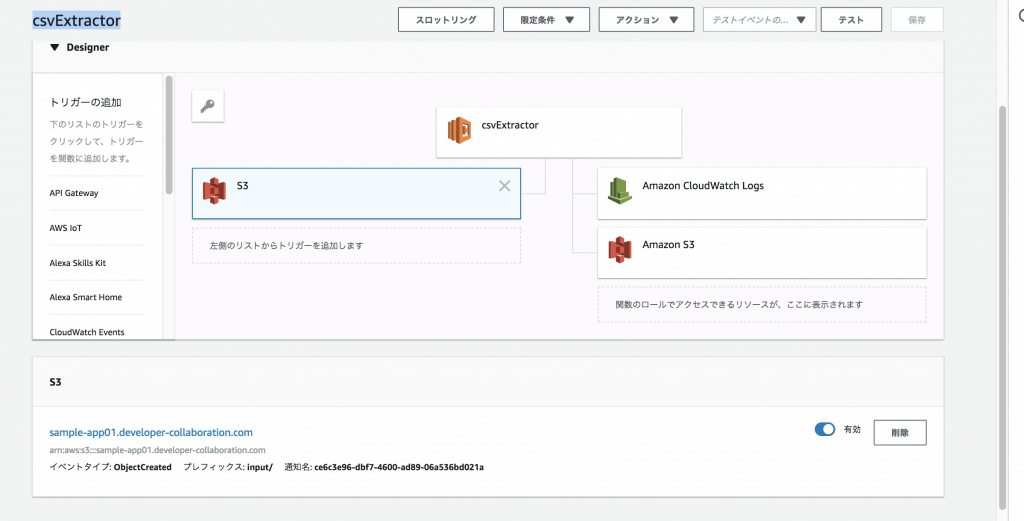
トリガーについて
トリガーは前回と同じですが以下のような形で設定となります。
バケットのプレフィックスに「input/」がついています。
関数について
さて、次に関数コードについて。
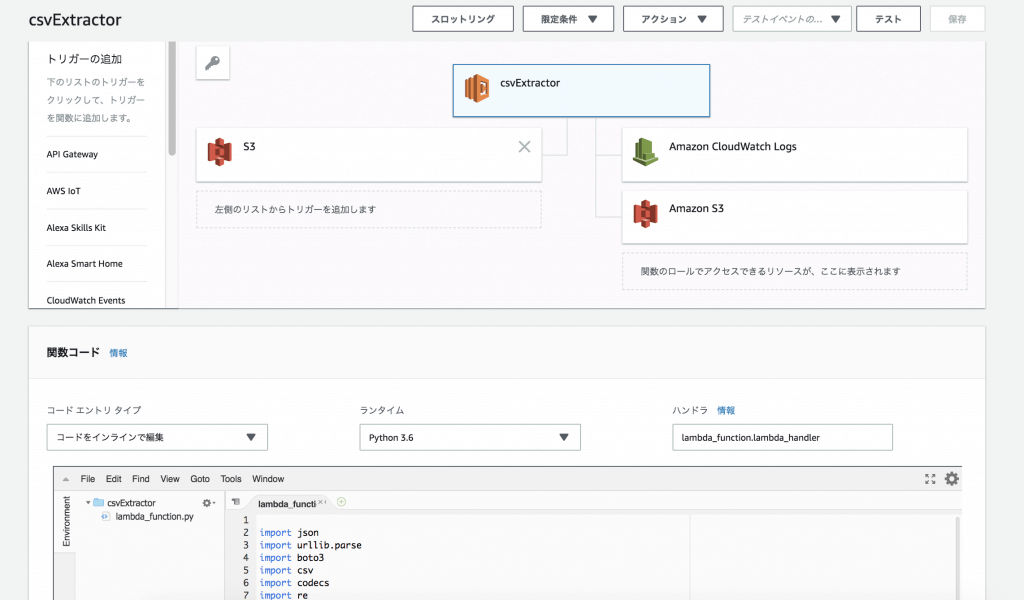
ランタイムとして「Python 3.6」を使用しています。
「lambda_function.py」というファイルを起動するので、ハンドラは「lambda_function.lambda_handler」となります。
今回、S3へのファイルの読み書きをするので実行ロールにS3への読み書きをつける必要があります。
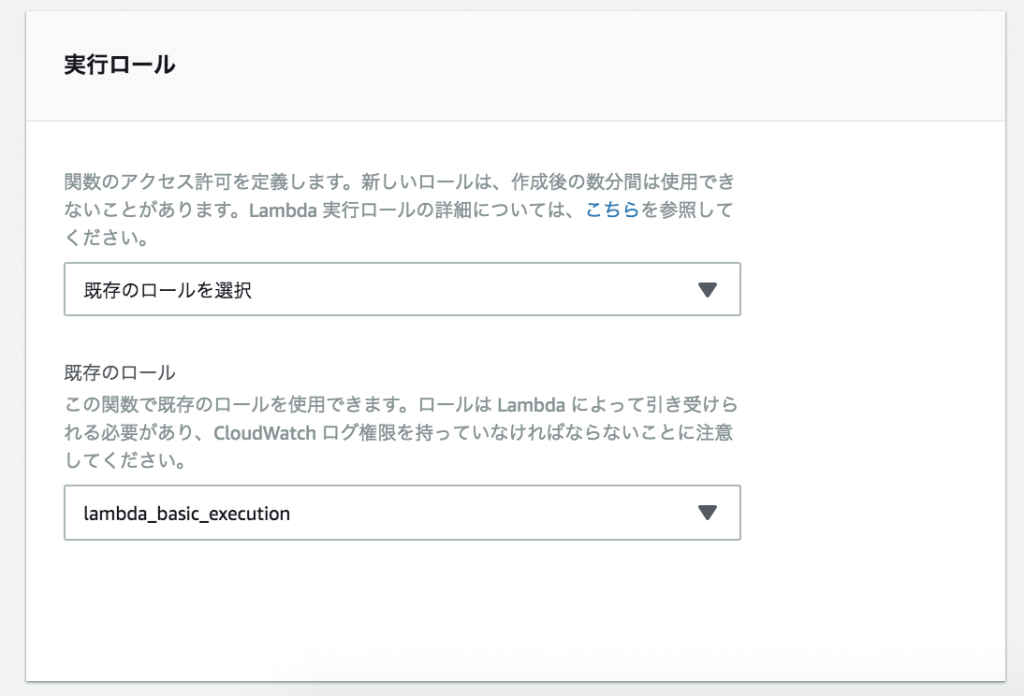
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:*:*:*", "arn:aws:s3:::*/*" ] } ] } |
さて、「lambda_function.py」の中身です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
import json import urllib.parse import boto3 import csv import codecs import re print('Loading function') s3 = boto3.client('s3') class OutputDocument: def __init__(self, id, name, description): self.id = id self.name = name self.description = description def create_dictionay(self): return {"id": self.id, "name": self.name, "description": self.description} # S3にアップロード def upload_file(bucket_name, file_key, bytes): out_s3 = boto3.resource('s3') s3Obj = out_s3.Object(bucket_name, file_key) res = s3Obj.put(Body = bytes) return res def lambda_handler(event, context): # Get the object from the event and show its content type input_bucket = event['Records'][0]['s3']['bucket']['name'] input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') output_bucket = input_bucket output_key = re.sub('^input', 'output', input_key).replace(".csv", ".json") try: response = s3.get_object(Bucket=input_bucket, Key=input_key) lines = response[u'Body'].read().decode('utf-8').split() text_string = "" for row in csv.reader(lines): document = OutputDocument(row[0], row[1], row[2]) json_text = json.dumps(document.create_dictionay(), ensure_ascii=False) text_string = text_string + json_text + "\n" upload_file(output_bucket, output_key, bytes(text_string, 'UTF-8')) except Exception as e: print(e) print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket)) raise e |
幾つかimportはしていますが、外部モジュールは使用していないので「lambda_function.py」の、1ファイルで実行しています。
関数の確認
まず、基本的なところで「def lambda_handler(event, context)」について。
こちらのコードでは「lambda_handler」という関数を定義しています。
ハンドラが「lambda_function.lambda_handler」なので、「lambda_function.py」の「lambda_handler」が実行されます。
最初の引数の「event」ではこの関数の実行時に呼び出されるイベントの情報がディクショナリ型で提供されます。
次に「context」の引数でランタイム情報(関数のタイムアウトまでの残り時間や実行中の関数のバージョン、設定されたメモリサイズなど)が提供されます。
また、この関数では戻り値として以下の値を返します。
同期型(RequestResponse)
関数の戻り値をLambda関数の呼び出し元へと返します。
非同期(Event)
関数の戻り値はかえりません。値がセットされていたとしても破棄されます。
何も返されない場合、nullという文字列が返されます。
今回のS3イベントでは非同期なので戻り値はありません。
CloudWatchでの確認
最終的な状況をCloudWatchで確認すると以下のようになります。
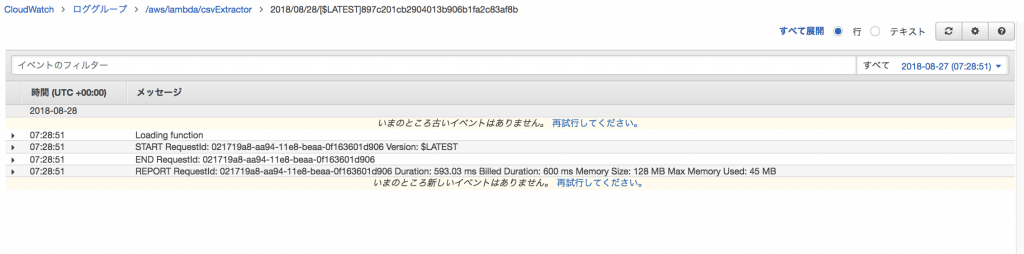
実行中のログなどは出していないのでエラーが出なければスッキリのログになります。
最終的なアウトプット
また、最終的なアウトプットのファイルは以下のようになりました。
|
1 2 3 4 |
{"id": "1", "name": "テスト", "description": "AAA"} {"id": "2", "name": "テスト2", "description": "BBB"} |
実際の運用ではエラー処理でコードは大きくなりそうですが、基本的には色々な処理の前段ではありかなというベースができました。
【関連記事】
・AWS LambdaでS3にファイルがアップロードされたのを検知する
・外部のライブラリを利用してのAWS Lambdaの設定
・AWS Lambdaをpython-lambda-localとlambda-uploaderを使ってローカル開発してみる
このブログは株式会社CoLabMixによる技術ブログです。
GCP、AWSなどでのインフラ構築・運用や、クローリング・分析・検索などを主体とした開発を行なっています。
Ruby on RailsやDjango、Pythonなどの開発依頼などお気軽にお声がけください。
開発パートナーを増やしたいという企業と積極的に繋がっていきたいです。